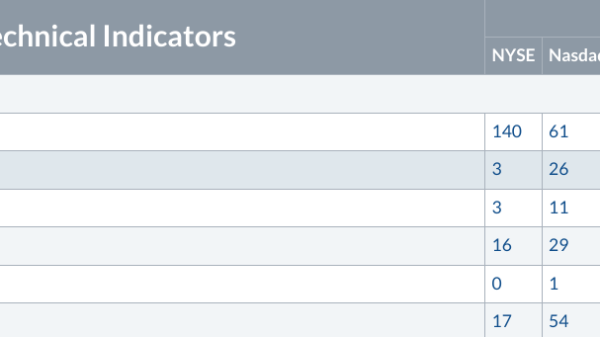









In the weeks leading up to the release of OpenAI’s newest “reasoning” model, o1, independent AI safety research firm Apollo found a notable issue. Apollo realized the model produced incorrect outputs in a new way. Or, to put things more colloquially, it lied.
Sometimes the deceptions seemed innocuous. In one example, OpenAI researchers asked o1-preview to provide a brownie recipe with online references. The model’s chain of thought — a feature that’s supposed to mimic how humans break down complex ideas — internally acknowledged that it couldn’t access URLs, making the request impossible. Rather than inform the user of this weakness, o1-preview pushed ahead, generating plausible but fake links and descriptions of them.
While AI models…